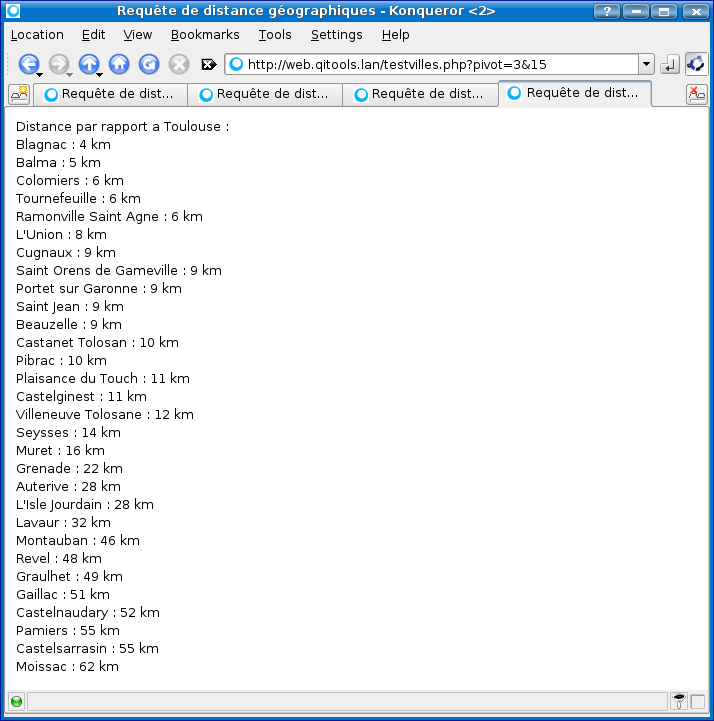
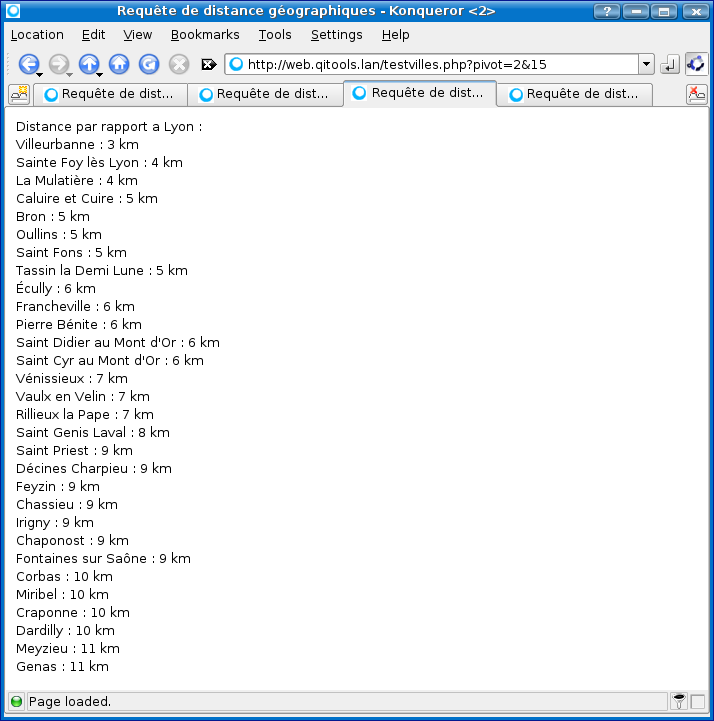
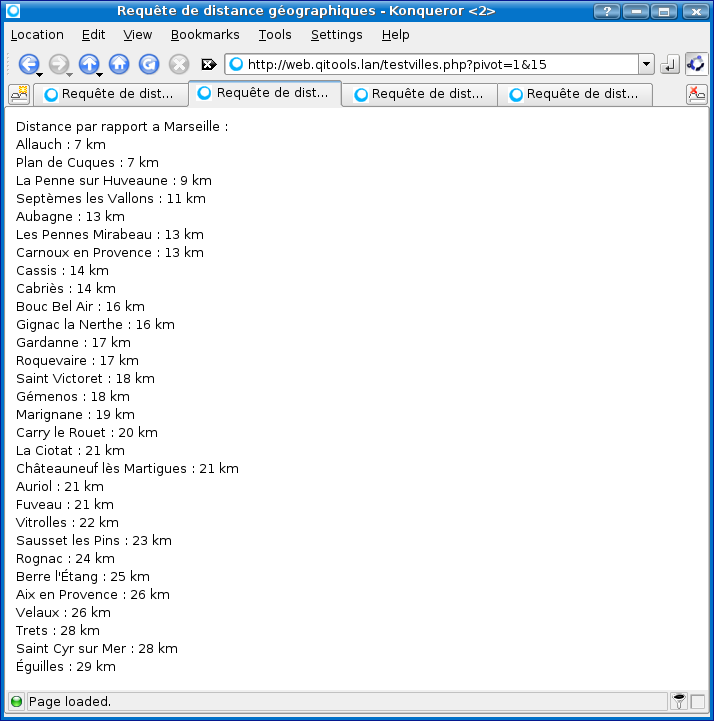
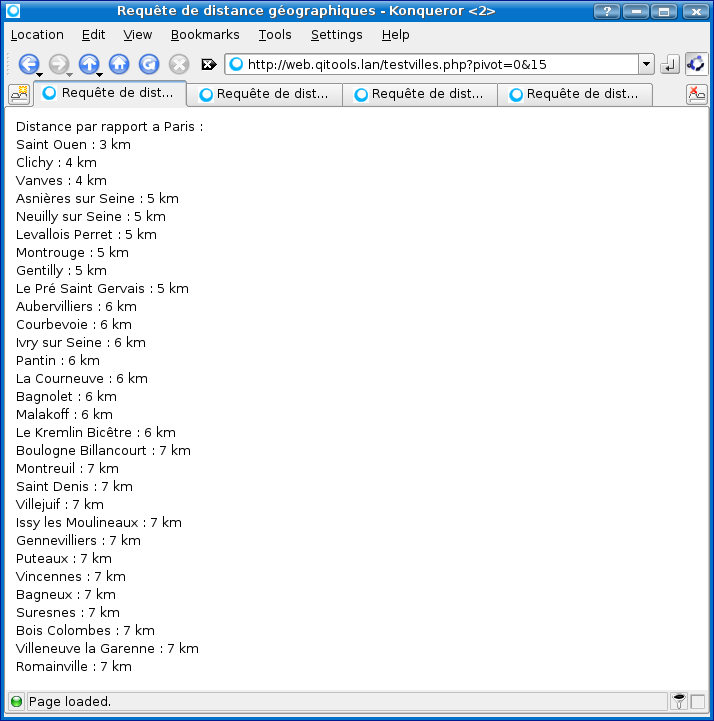
Zone de détente pour stocker tous les scripts qu'il m'est arrivé de faire pour le plaisir (si, si, c'est vrai), pour le travail ou pour répondre à un besoin bien précis. La plupart ne doivent pas être optimisés et doivent bien exposer mes manques de connaissance globaux de Bash/Linux, mais, comme on dit en Californie du moment que ça marche.
Télécharger une collection de Mod/XM/S3M
Si, comme moi, vous aimez les modules Amiga de la belle époque, ce petit script va vous plaire : il rapatrie l'ensemble de la collection du site Amiga Module Preservation et ceci sans s'embêter. �?a me permet d'illustrer l'intérêt de la conjonction de sed et awk (ou la version de GNU, gawk) pour écrire des scripts très courts qui peuvent faciliter la vie (et entre autre les tâches d'admin).
Pour l'instant je remplis un fichier (modlist) avec les URLs de tous les modules, il reste quelques lignes à écrire pour les télécharger effectivement.
#!/bin/bash
#Ou comment choper tous les modules Amiga qu'on veut en un seul coup
#TODO : décompresser les gz on the fly
#TODO : fournir simplement la liste des fichiers
RootURL=\"http://amp.dascene.net/modules/\"
wget -O amp.download \$RootURL
#On déduit les dossiers à choper
for folder in `cat amp.download | sed -n 's/^.*<a href=\"\([^\"]*\)\">\1.*$/\1/p'`; do
:>artistslist
wget -O amp.download.tmp $RootURL/$folder
cat amp.download.tmp | sed -n 's/^.*<a href=\"\([^\"]*\)\">\\1.*\$/\1/p' | awk '{ print "'$folder'\"$0 }' >> artistslist
for artist in `cat artistslist`; do
:>modlist
wget -O artist.page $RootURL$artist
cat artist.page | sed -n 's/^.*<a href=\"\([^\"\/?]\+\)\">.*$/\1/p' | awk '{ print "'$RootURL$artist'"$0 }' >> modlist
for module in `cat modlist`; do
Path=${module%/*}
Artist=${Path##*/}
ModName=${module##*/}
mkdir -p ${Artist:0:1}$Artist
wget -P ${Artist:0:1}$Artist/ $module
done
done
done
rm -f amp.download artist.page modlist amp.download.tmp
Nettoyage des noms des modules
Une fois les modules précédents téléchargés, on se rend compte que les habitudes de nommage de fichiers ne correspondent pas à ceux en vigueur actuellement, on peut facilement les renommer avec le script suivant :
Dir="Jester"; for item in $Dir/MOD*; do NewName=$(echo `basename ${item}` | awk 'BEGIN{FS="."} {print $2"."tolower($1)}'); mv "$item" "$Dir/$NewName"; doneLe dossier et l'extension sont en dur, mais c'est un exemple
Commandes Bash intéressantes
Ne riez pas mais ça faisait un bout de temps que je voulais avoir la possibilité de trier des fichiers par taille (ou tout autre critère) mais sans avoir jamais vraiment cherché. C'est fait, et c'est très facile.
//Trier la sortie de ls -l (aka ll) en fonction la taille des fichiers (descendant).
ls -l | sort -nrk 5,5
//Pour les trier dans l'ordre ascendant il faut virer le 'r' de sort.
//Extension : renvoie les 4 plus gros fichiers (il faut virer la 1ère ligne de ls -l qui est la taille totale).
ls -l | awk 'BEGIN{i=0}{if (i++) print $0}' | sort -rnk 5,5 | tail -n 4
//Pour les 4 plus petits, il faut virer le 'r' de sort.
//Mais on peut arranger le bloc awk par une commande sed (c'est très original...)
ls -l | sed -n '1!p' | sort -rnk 5,5 | tail -n 4
//C'est équivalent : on dit à sed de faire le contraire d'imprimer (flag p) la ligne 1.
//Si on veut trier par date, le tri par nombre (-n) ne va plus il faut trier les chaînes directement (-d), ce qui donne :
ls -l | sed -n '1!p' | sort -rdk 6,6 | tail -n 4
//Et on trie alors par date croissante (les plus récents en dernier)Petite application : imaginons que l'on ait un ensemble de dossiers contenant chacun plusieurs fichiers (par exemple des PDF de docs amassés dans plusieurs domaines), comment avoir les fichiers triés du plus petit au plus gros ? Réponse :
for file in */*; do [[ -f $file ]] && echo `ls -l "$file"`; done | sort -nrk 5,5
Bien penser au guillemets qui encadre $file sinon un fichier ayant un nom avec des espaces va provoquer un bordel...
La version deux ci-dessous de ce oneliner peut paraître plus compliquée mais une fois sauvée dans un script et placée dans le PATH elle convient à tout ce dont j'ai besoin. Elle permet d'utiliser l'option -0 de la commande ls qui gère tous les types de noms de fichiers.
find . -name "*pdf" -print0 | xargs -0 ls -l | awk '{ O=""; for (i=8; i<=NF; i++) O=O$i; print $5" "O;}' | sort -rnk1,1Si on appelle le script précédent findex on peut ainsi de chercher tous les fichiers PDF et de les ordonner à partir du répertoire courant et dans tous ses sous-répertoires en une seule ligne intuitive : findex . pdf.
Tagage, classement et indexation automatiques de données textuelles
Je cherche à calculer une empreinte d'un texte à partir des mots qui le constitue.
cat <mon_fichier> | sed -e "s/''/\n/g" | sed -e 's/ /\n/g' -e 's/[=:;,\{\}"\$<>&|#\*\(\)\\\/\-\?\+\.]/ /g' | sed -e 's/ /\n/g' | sort | uniq -c | sort -n
En ignorant la casse, en filtrant les mots inutiles (les plus courants etc), en les triant par taille et en n'en gardant que 10, on commence à pouvoir tagguer automatiquement un bloc de texte.
cat <mon_fichier> | sed -e \"s/\'\`/\\n/g\" | sed -e 's/ /\\n/g' -e 's/[=:;,\{\}\"\\$<>&|#\*\(\)\\\/\-\?\+\.]/ /g' | sed -e 's/ /\\n/g' | tr 'A-Z' 'a-z' | sort | uniq -c | sort -n | awk -f filter.awk | sort -nk 3,3 | tail | awk '{print $2}'
Voilà le résultat avec un bout de descriptif de Awk :
consecutive
declaration
differences
fundamental
programming
additionally
conceptually
corresponding
superficially
one-dimensional
LDD extended
Je ne sais pas vraiment si ce script est utile : peut-être ldd fait-il déjà tout ce travail, mais je n'en ai pas l'impression. Toujours est-il que je voulais obtenir le résultat de ldd pour un exécutable et ensuite pour chacune des librairies renvoyées. D'où ce script qui m'a bien énervé, surtout pour le passage de tableau à la fonction contains...
#!/bin/bash
function displayHelp
{
echo "Extension de récursive de <ldd> :"
echo "affiche toutes les librairies en dépendance d'une autre ou d'un exécutable"
echo "et affiche les dépendances des dépendances ad finitum."
echo
echo "Syntaxe :"
echo
echo " $0 <exelibs>+|--help|--version"
echo
echo "Options :"
echo
echo "<exelibs>+ : suite d'exécutables ou de librairies dont on veut les dépendances."
echo
echo "--help : cette page d'aide."
}
#Vérifie que ${1} n'est pas contenu dans le tableau dont le nom est passé en second paramètre
function contains
{
Value="${1}"
ArrName=${2}
Arr=\${"$ArrName"[@]}; Arr=`eval echo $Arr`
Temp=( ${Arr[@]/$Value/XXX$Value} )
Verif=( ${Arr[@]} )
Str=${Temp[@]}; Len1=${#Str}
Str=${Verif[@]}; Len2=${#Str}
[[ $Len1 != $Len2 ]] && return 0;
return 1
}
NbParams=${#*}
[[ $NbParams == 0 ]] && echo "Pas de paramètres : il faut le chemin d'une librairie ou d'un exécutable." && echo && displayHelp && exit 1;
while [[ true ]]; do
[[ ${#*} == 0 ]] && break;
CurBinary=${1}
shift
[[ $CurBinary == "--help" ]] && displayHelp && continue;
echo "Examen de $CurBinary :"
[[ ! -f $CurBinary ]] && echo "Le fichier n'existe pas !" && continue;
unset Todo; unset Handled
Todo[0]=$CurBinary
PassIndex=0
while [[ ${#Todo[@]} != 0 ]]; do
# echo "Passe $PassIndex : il reste "${#Todo[@]}" élément(s) à examiner"
for lib in ${Todo[@]}; do
List=( `ldd $lib | awk '{if ($1!~"linux-gate" && $1!~"statically") { if (!length($3)) print $1"\n"$1; else print $1"\n"$3}}'` )
let "nbLibs = -1 + ${#List[@]} / 2"
for i in `seq 0 $nbLibs`; do
LibName=${List[((i*2))]}
LibPath=${List[((2*i+1))]}
contains $LibPath Handled; Ret1=$?
contains $LibPath Todo; Ret2=$?
if [[ $Ret1 -eq 1 ]]; then
if [[ $Ret2 -eq 1 ]]; then
Todo[${#Todo[@]}]=$LibPath #On l'ajoute au tableau todo
fi
fi
done
newArray=( ${Todo[@]%$lib} ); unset Todo; Todo=( ${newArray[@]} )
contains $lib Handled; Ret=$?
if [[ $Ret -eq 1 ]]; then Handled[${#Handled[@]}]=$lib; fi
done
((PassIndex++))
done
let "MaxItemsIndex = ${#Handled[@]} -1"
for i in `seq 1 $MaxItemsIndex`; do echo ${Handled[$i]}; done
doneCopie de CDs
Un petit script sans aucune prétention mais que j'apprécie beaucoup pour m'aider à copier mes cds sur un disque dur sans avoir à utiliser de souris ou de commandes répétitives. Il crée un dossier par CD, place tout à l'intérieur, modifie les droits d'écriture et sort le CD du lecteur en me disant si des erreurs se sont produites. Je l'appelle généralement depuis l'endroit ou je veux stocker les données avec le commande : grabcd /media/cdrom
#!/bin/bash
[[ ${#} -ne 1 ]] && echo "J'attends la partition source..." && exit 1;
Src="${1}"
ErrorLog="./errors.log"
rm -f $ErrorLog
mount $Src 2> /dev/null
let NbFolders=`ls -ld cd* 2> /dev/null | wc -l`+1
Dest=cd$NbFolders
mkdir $Dest
cp -vr $Src/* $Dest/ 2>$ErrorLog
chmod -R u+w $Dest/
[[ -s $ErrorLog ]] && echo "Des erreurs de lecture se sont produites :" && cat $ErrorLog;
eject
Taux de changes
Pour obtenir le taux de conversion du dollar face à l'euro (en gros combien il faut de dollars pour avoir un euro) il suffit d'utiliser ce script :
wget -q -O- www.federalreserve.gov/releases/h10/Update/ | awk '{if ($2=="MEMBERS" && $3=="EURO") print $NF}'J'aime beaucoup l'option de wget -O- pour envoyer la ressource HTTP téléchargée sur stdout, très pratique !
(Dé)Compression de plusieurs dossiers (archives)
Parcours de tous les dossiers du répertoire courant et crée une archive BZ2 pour chacun en indiquant la progression totale (attention aux dossiers contenant des espaces...).
fList=`find -maxdepth 1 -type d | tail -n+2`; nb=0; for item in $fList; do echo -n "Dossier : $item..."; tar cjf "$item.tar.bz2" "$item"/*; ((nb++)); echo $(echo "scale=1; 100*$nb/`echo "$fList" | wc -l`" | bc)" %"; done
Ajout automatique de domaines à un serveur DNS
Voici un script autosuffisant (pas besoin de ressource externe) pour ajouter ou modifier un domaine auprès de Bind. �?a évite de s'embêter à éditer et/ou copier-coller des fichiers, ça fait tout tout seul.
Bien sûr rien de compliqué mais au moins c'est disponible.
#!/bin/bash
function displayHelp
{
echo "Ajoute un domaine à Bind et en option relance ce serveur."
echo && echo "Syntaxe :"
echo " $0 [--add <domain>] [--label <label>] [--restart] [--help]"
echo && echo "Options :"
echo && echo " --add <domain> : ajoute le domaine <domain> à la liste des zones gérées par Bind."
echo && echo " --label <txt> : ajoute le champ texte <txt> à la zone DNS (via une ligne TXT)."
echo && echo " --restart : redémarre le serveur de nom pour qu'il prenne en compte toutes ses zones."
echo && echo " --help : affiche cette aide (équivalent à appeler ce programme sans aucun paramètre)."
echo && echo "###TODO : reste à modifier le fichier principal de configuration de Bind."
echo && echo "(c) Qitools 2007."
}
function createNamedFile
{
domainName=$1
domainHost=$2
hostIP=$3
label=$4
#Création d'un fichier temporaire contenant la template de la zone
TempFileName=mktemp
echo "; The zone file for the %domainName% domain
\$TTL 3D
%domainName%. IN SOA ns.%domainName%. postmaster.%domainName%. (
%date%
2M
1M
1W
1H )
TXT \"%label%\"
IN NS ns.%domainName%.
IN NS ns.ovh.net.
MX 10 mail.%domainName%.
localhost IN A 127.0.0.1
ns IN A %domainIP%
mail IN A %domainIP%
%domainName%. IN A %domainIP%
www IN CNAME %domainHost%.
" > $TempFileName
#Transformation de la template
cat $TempFileName | sed "s/%domainName%/$domainName/g" | sed "s/%domainIP%/$hostIP/g" | sed "s/%domainHost%/$domainHost/g" > $TempFileName.1
if [[ ${#label} != 0 ]]; then
cat $TempFileName.1 | sed "s/%label%/$label/g" > $TempFileName.2
else
cat $TempFileName.1 | sed "/%label%/d" > $TempFileName.2
fi
#Gestion épineuse de la date...
ZoneFile=/var/named/zones/$domainName
ZoneDir=`dirname $ZoneFile`
mkdir -p $ZoneDir
if [[ -f $ZoneFile ]]; then
OldDate=`cat $ZoneFile | grep "$domainName.*IN.*SOA" --after-context=1 | tail -n +2 | awk '{print $1}'`; OldRev=${OldDate:8}
#On nettoie la chaîne des 0 en préfixe sinon le let suivant ne fonctionnera pas
OldRev=`echo $OldRev | sed "s/^0*//g"`
let OldRev++
OldRev=`printf "%02d\n" $OldRev`
ZoneDate="`date +%Y%m%d`$OldRev"
else
ZoneDate="`date +%Y%m%d`01"
fi
#on reprend la date existante et on incrémente la révision
cat $TempFileName.2 | sed "s/%date%/$ZoneDate/g" > $ZoneFile
#Arrivé ici on peut ajouter quelque chose au fichier /etc/named.conf si ça n'est pas déjà fait...
MainBindConf="/etc/named.conf"
#Soit on ajoute un bloc de zone soit on réécrit le bloc correct (on ne sait jamais)
}
RestartNamed=false
[[ ${#} == 0 ]] && displayHelp && exit 0;
while [[ ${#} -gt 0 ]]; do
Param=$1
case $Param in
"--help") displayHelp && exit 0;;
"--add") shift; Domain=$1;;
"--label") shift; ZoneLabel=$1;;
"--restart") RestartNamed=true;;
".*") echo "Option <$Param> inconnue !";;
esac
shift
done
#On nettoie le nom de domaine...
Domain=`echo $Domain | tr [A-Z] [a-z] | sed "s/ //g" | sed "s/\///g"`
#On vérifie qu'on est bien root
[[ `id -u` != 0 ]] && echo "Ce script nécessite d'être en root pour fonctionner." && exit 3;
#Vérifier que named tourne bien ou du moins qu'il existe...
NamedRunning=`ps -Af | grep [n]amed | head -n 1 | awk '{print $1}'`
if [[ $NamedRunning != "named" ]]; then
#Le serveur Bind ne tourne pas, on va vérifier qu'il existe quand même sur la machine
NamedPath=`which named`
[[ $? == 1 ]] && echo "Le serveur de nom Bind n'existe pas, le script ne sert à rien sur cette machine." && exit 4;
fi
[[ $RestartNamed -eq "false" && ${#Domain} -eq 0 && ${#MainDNSServer} -eq 0 ]] && echo "Aucune option sélectionnée." && exit 2;
CurrentHost=`hostname`
CurrentHostIP=`host $CurrentHost | sed '/alias/d' | sed '/NXDOMAIN/d' | head -n 1 | awk '{print $4}'`
[[ ${#CurrentHostIP} -eq 0 ]] && echo "Aucune adresse IP trouvée pour le domaine <$CurrentHost>. Vérifiez votre entrée et recommencez." && exit 1;
createNamedFile $Domain $CurrentHost $CurrentHostIP "$ZoneLabel"
if [[ $RestartNamed == "true" ]]; then
/etc/init.d/named stop 1>/dev/null
/etc/init.d/named start 1>/dev/null
fi
Récupérer ses mots de passe Windows
Une petite note pour me souvenir de la façon dont on récupère les mots de passe d'une install de Windows sur le même PC qu'un Linux.
Ici j'utilise (K)Ubuntu, mais la logique est suffisamment simpliste pour être adapté sur n'importe quelle distribution.
En tous cas ça m'a permis de récupérer facilement mon mot de passe root - pardon Administrator - que j'avais oublié, n'ayant pas démarré Windows depuis un bon bout de temps...
#Installe les softs qui peuvent manquer
apt-get install bkhive samdump2 john
#On récupère la SYSKEY
bkhive /media/hda1/WINNT/system32/config/system syskey
#On utilise la SYSKEY pour décrypter les hash des mots de passe
samdump2 /media/hda1/WINNT/system32/config/SAM syskey > hashes
#On cherche les mots de passe dont on connaît les hash
john hashes
J'ai extrait ces infos de cette page intéressante. D'autres informations peuvent être obtenues depuis la page de John The Ripper, logiciel utilisé pour réellement cracker les mots de passe.
ImageMagick sympathique
Je devais faire des manipulations sur des images et forcément le réflexe est d'utiliser ImageMagick ! Le problème était que j'avais une petite centaine de feuilles papier dont les numéros en bas de page étaient incorrects et qui devait produire un PDF regroupant deux pages d'origine par page. J'ai créé deux dossiers, un dossier jpg/ pour les fichiers nettoyés et un autre doubles/ pour les images finales. Le script est :
i=1; j=0; k=0; for item in *png; do echo $item; convert "$item" -fill white -draw 'rectangle 484,3256,2184,3516' -fill black -font "Times-Bold" -pointsize 60 -draw "text 1300,3400 {$i}" -quality 80 "jpg/page_"$j"_"$k".jpg"; ((i++)); ((k++)); [[ $k == 2 ]] && k=0 && ((j++)); done
for i in `find product/*jpg | awk 'match($0,"page_([0-9]+)",a) {print a[1]}' | sort -nk1,1 | uniq`; do PicIndex=`echo "0"$i | awk '{print substr($0, length($0)-1, 2)}'`; echo $i; montage "jpg/page_"$i"_0.jpg" "jpg/page_"$i"_1.jpg" -geometry +2+2 "doubles/page_"$PicIndex".jpg"; done
convert -monitor doubles/*jpg -monitor -compress jpeg dest.pdf
La première ligne efface le numéro de page existant et le remplace par quelque chose de standardisé et en profite pour nommer les fichiers produits de manière à préparer l'étape suivante. Etape qui justement, sur la deuxième ligne, crée des images contenant des groupes de deux images combinées. La dernière ligne générant le fichier PDF voulu.
Commandes Ubuntu pour la gestion des paquets
Quelques commandes pour se faciliter la vie sous Debian/Ubuntu :
Repair:dpkg --configure -a
Reconfigure:dpkg-reconfigure pkg (-a)
Fix:apt-get -f install (pkg)
Nuke:dpkg --force-remove-reinstreq -r pkg
Corrupt deb:rm /var/cache/apt/archives/pkg
Hack dpkg:rm /var/lib/dpkg/info/pkg*
Mon fichier sources.list
#
deb cdrom:[Ubuntu-Server 6.10 _Edgy Eft_ - Release i386 (20061025.1)]/ edgy main restricted
deb http://fr.archive.ubuntu.com/ubuntu/ edgy main restricted
deb-src http://fr.archive.ubuntu.com/ubuntu/ edgy main restricted
## Major bug fix updates produced after the final release of the
## distribution.
deb http://fr.archive.ubuntu.com/ubuntu/ edgy-updates main restricted
deb-src http://fr.archive.ubuntu.com/ubuntu/ edgy-updates main restricted
deb http://fr.archive.ubuntu.com/ubuntu edgy-security main restricted
deb http://fr.archive.ubuntu.com/ubuntu edgy-proposed main restricted
deb-src http://fr.archive.ubuntu.com/ubuntu edgy-security main restricted
deb-src http://fr.archive.ubuntu.com/ubuntu edgy-proposed main restricted
deb http://fr.archive.ubuntu.com/ubuntu edgy universe multiverse
deb http://fr.archive.ubuntu.com/ubuntu edgy-updates universe multiverse
deb http://fr.archive.ubuntu.com/ubuntu edgy-security universe multiverse
deb http://fr.archive.ubuntu.com/ubuntu edgy-proposed universe multiverse
deb-src http://fr.archive.ubuntu.com/ubuntu edgy universe multiverse
deb-src http://fr.archive.ubuntu.com/ubuntu edgy-updates universe multiverse
deb-src http://fr.archive.ubuntu.com/ubuntu edgy-security universe multiverse
deb-src http://fr.archive.ubuntu.com/ubuntu edgy-proposed universe multiverse
deb http://archive.canonical.com/ubuntu edgy-commercial main
deb http://kubuntu.org/packages/kde-latest edgy main
deb-src http://kubuntu.org/packages/kde-latest edgy main
deb http://kubuntu.org/packages/koffice-latest edgy main
deb-src http://kubuntu.org/packages/koffice-latest edgy main
deb http://kubuntu.org/packages/amarok-latest edgy main
deb-src http://kubuntu.org/packages/amarok-latest edgy main
deb http://medibuntu.sos-sts.com/repo/ edgy free non-free
deb-src http://medibuntu.sos-sts.com/repo/ edgy free non-free
deb http://ubuntu.beryl-project.org edgy all
deb-src http://ubuntu.beryl-project.org edgy all
deb http://gandalfn.club.fr/ubuntu/ edgy stable
deb-src http://gandalfn.club.fr/ubuntu/ edgy stable
deb http://ubuntu.beryl-project.org/ edgy main
deb http://www.albertomilone.com/drivers/edgy/latest/32bit binary/
## Uncomment the following two lines to add software from the 'universe'
## repository.
## N.B. software from this repository is ENTIRELY UNSUPPORTED by the Ubuntu
## team, and may not be under a free licence. Please satisfy yourself as to
## your rights to use the software. Also, please note that software in
## universe WILL NOT receive any review or updates from the Ubuntu security
## team.
# deb http://fr.archive.ubuntu.com/ubuntu/ edgy universe
# deb-src http://fr.archive.ubuntu.com/ubuntu/ edgy universe
## Uncomment the following two lines to add software from the 'backports'
## repository.
## N.B. software from this repository may not have been tested as
## extensively as that contained in the main release, although it includes
## newer versions of some applications which may provide useful features.
## Also, please note that software in backports WILL NOT receive any review
## or updates from the Ubuntu security team.
# deb http://fr.archive.ubuntu.com/ubuntu/ edgy-backports main restricted universe multiverse
# deb-src http://fr.archive.ubuntu.com/ubuntu/ edgy-backports main restricted universe multiverse
deb http://security.ubuntu.com/ubuntu edgy-security main restricted
deb-src http://security.ubuntu.com/ubuntu edgy-security main restricted
# deb http://security.ubuntu.com/ubuntu edgy-security universe
# deb-src http://security.ubuntu.com/ubuntu edgy-security universe